Ultralytics YOLO11 model fails to load on OwLite GUI

Dear OwLite Team,
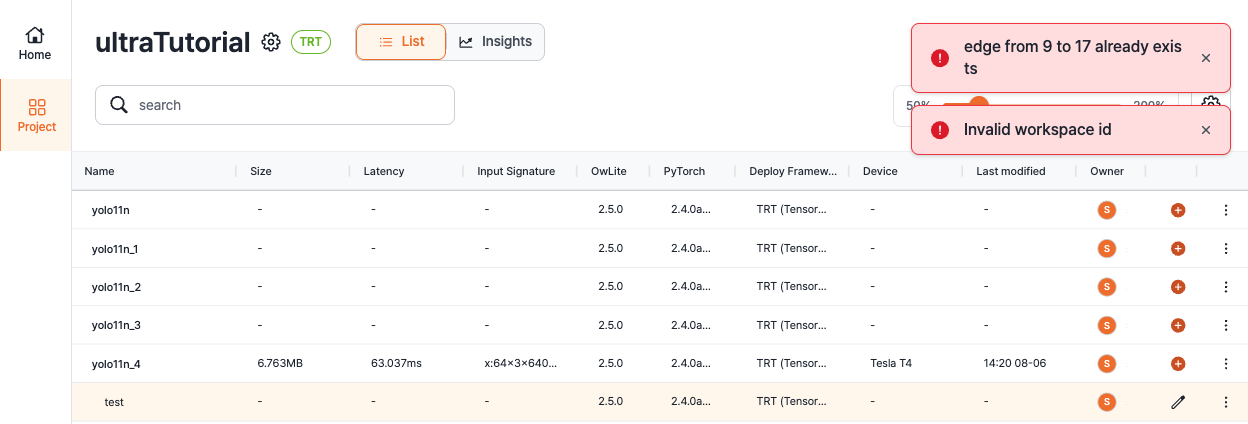
We are trying to quantize the off-the-shelf YOLO11 model as provided by the ultralytics repo. We, however, quickly encounter an issue as shown in the attached image below: OwLite successfully exports YOLO11 to onnx, engine and bin files (it even measures the latency and memory footprint with no problem!), but it fails to load the ONNX graph. Concretely, clicking the pencil icon – which should normally open the GUI to customize layer-wise quantization – throws two errors that say (1) ‘edge from 9 to 17 already exists’, and (2) ‘Invalid workspace id’.
I also attach the code below which can be used to reproduce the error.
>>> pip install ultralytics
from contextlib import contextmanager
from copy import deepcopy
import torch
import owlite
import ultralytics
from ultralytics.nn.modules import Detect, C2f
if __name__ == "__main__":
batch_size = 64
device = "cuda"
# Load the model
model = ultralytics.YOLO("yolo11n.pt")
model = model.model
# Update model
model = deepcopy(model).to(device)
for p in model.parameters():
p.requires_grad = False
model.eval()
model.float()
model = model.fuse()
# Modify the torch model
for m in model.modules():
if isinstance(m, Detect):
m.dynamic = False
m.export = True
m.format = "onnx"
m.max_det = 300
m.xyxy = True
elif isinstance(m, C2f):
m.forward = m.forward_split
# Dry run
example_input = torch.randn(batch_size, 3, 640, 640).to(device)
y = model(example_input)
# Standard OwLite workflow
owl = owlite.init(project="ultraTutorial", baseline="yolo11n")
model = owl.convert(model, example_input)
owl.export(model)
owl.benchmark()I appreciate the support in advance.
San
-
Official comment

Dear San,
Thank you for reaching out and for your detailed report. We appreciate you taking the time to provide the error description and the code snippet to reproduce it.
I have forwarded the issue to our engineering team. They are now looking into the errors you encountered ('edge from 9 to 17 already exists' and 'Invalid workspace id') when trying to open the layer-wise quantization GUI.
As YOLOv11 is not yet officially part of our
owlite-examples, you may have run into an untested compatibility issue. We can see from your screenshot that you successfully built the TensorRT engine and completed the benchmark, which is very helpful information for our debugging process. Our team will use the code you shared to reproduce the problem and work on a fix.Since this is a model we have not previously validated, the investigation may take some time. We plan to provide you with a progress update by this coming Monday afternoon. If we foresee any delays, we will be sure to inform you.
Thank you for your patience and for helping us improve OwLite.
Best regards,
The OwLite Team
-
Dear San,
Here is the updated recommendation to solve the ONNX graph loading error.
1. Disable theforward_splitmethod- Please comment out the lines that modify the
C2fmodule’s forward pass, as previously suggested. The action remains the same, but the reasoning is now more accurate.
Recommended action
# Modify this part of your code # elif isinstance(m, C2f): # m.forward = m.forward_splitReasoning
- Our engineer clarified that the
forward_splitmethod is indeed intended to create a cleaner ONNX. However, despite its intention, this specific implementation within YOLOv11 appears to be causing a conflict with our graph parser. By disabling it, the model will revert to its standardforwardmethod, which should resolve the loading error in OwLite and allow you to proceed.
2. Remove the
model.fuse()Call- We still recommend removing the
model.fuse()line from your script.
Recommended action:
# Modify this part of your code # model = model.fuse()Reasoning:
-
Redundancy: OwLite has its own built-in capability to fuse
Conv+BNlayers during the optimization process, so this step is not needed. -
Better Performance for QAT: For Quantization-Aware Training (QAT), it is often better to keep the Batch Normalization (BN) layers. The
model.fuse()command merges them into the convolution layers, which can sometimes hinder QAT performance.
Additional Guidance
- As you proceed, if you’re looking for a reference on how to structure your Post-Training Quantization (PTQ) or QAT process, we highly recommend looking at the
yolov8folder within ourowlite-examplesrepository. It provides a great template.
Please try these changes, and let us know if it resolves the error. Thank you again for helping us get the details right!
Best regards,
The OwLite Team1 - Please comment out the lines that modify the
-
Hello,
The suggested changes work with no errors!
Thank you again for the support.
San
0 -
Dear OwLite Team,
Following the issue discussed above, I was able to successfully export the model, perform PTQ and run
owlite.benchmark().Ultralytics has its own Exporter that allows users to export ultralytics' models to FP32, FP16, and INT8 engines. The advantage of OwLite over ultralytics' Exporter is that the former support QAT while the latter does not.
Nevertheless, we quickly ran experiments to compare the COCO mAP and latency of TRT engines exported via (1) OwLite, and (2) ultralytics. The results were underwhelming.
+-----------------------+-------+-------+-------+----------+-------------+ | Ultralytics' Exporter | P | R | mAP50 | mAP50-95 | Latency (ms)| +-----------------------+-------+-------+-------+----------+-------------+ | yolo11n.pt | 0.652 | 0.502 | 0.546 | 0.391 | 2.9 | +-----------------------+-------+-------+-------+----------+-------------+ | yolo11n_fp32.engine | 0.647 | 0.496 | 0.544 | 0.389 | 2.5 | +-----------------------+-------+-------+-------+----------+-------------+ | yolo11n_fp16.engine | 0.647 | 0.497 | 0.544 | 0.389 | 0.9 | +-----------------------+-------+-------+-------+----------+-------------+ | yolo11n_int8.engine | 0.639 | 0.483 | 0.527 | 0.372 | 0.6 | +-----------------------+-------+-------+-------+----------+-------------+ +--------------------+-------+-------+-------+----------+-------------+ | OwLite | P | R | mAP50 | mAP50-95 | Latency (ms)| +--------------------+-------+-------+-------+----------+-------------+ | Baseline | 0.644 | 0.474 | 0.521 | 0.369 | 0.9 | +--------------------+-------+-------+-------+----------+-------------+ | Exp1 | 0.623 | 0.461 | 0.503 | 0.348 | 0.6 | +--------------------+-------+-------+-------+----------+-------------+ *Baseline has no INT8 quantization layer. *Exp1 model follows OwLite's recommended INT8 configuration.As per the previous suggestion in the above thread, we have closely looked into the details under
yolov8folder in theowlite-examplesrepository and updated the codes accordingly. Namely,- we have removed conv + bn fusion before onnx export. (following suggested solution)
- we have updated the class SPPF's forward method. (following this file)
- y = [self.cv1(x)] - y.extend(self.m(y[-1]) for _ in range(3)) - return self.cv2(torch.cat(y, 1)) - + x = self.cv1(x) + y1 = self.m(x) + y2 = self.m(y1) + return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))- we have updated the class C2f's forward method. (following this file)
- y.extend(m(y[-1]) for m in self.m) + for m in self.m: + y.append(m(y[-1]))I am mainly trying to understand the reason why OwLite's
Exp1model shows inferior performance than ultralytics’ naiveyolo11n_int8.enginewhich is built usingconfig.set_flag(trt.BuilderFlag.INT8)andMINMAXcalibrator. (The details can be found here) I kindly ask for guidance that might help resolve the issue.Best regards,
San
0
Please sign in to leave a comment.
Comments
4 comments